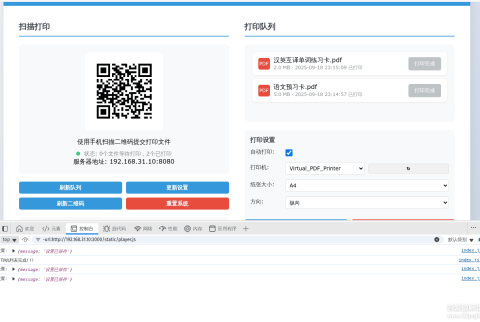
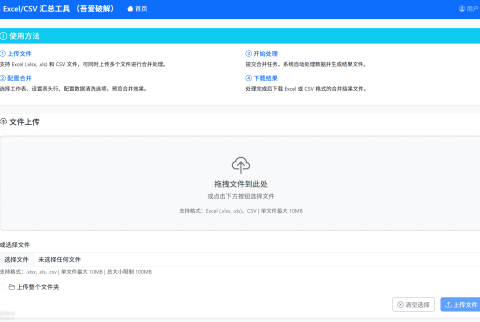
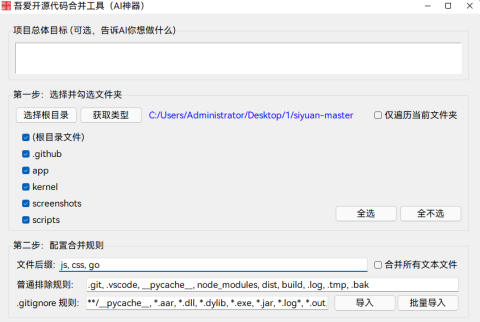
[Python] - from torch.utils.data import DataLoader
- from torch.utils.data import Dataset
- from torch.utils.tensorboard import SummaryWriter
- from torch import nn
- from torch.optim import Adam
- from torchvision import transforms
- import torch
- import os
- from PIL import Image
- captcha_array=list("0123456789")
- captcha_size=4
- def text2Vec(text):
- vec=torch.zeros(captcha_size,len(captcha_array))
- for i in range(len(text)):
- vec[i,captcha_array.index(text[i])]=1
- return vec
- def vec2Text(vec):
- vec=torch.argmax(vec,dim=1)
- text=""
- for i in vec:
- text+=captcha_array[i]
- return text
- class vkmodel(nn.Module):
- def __init__(self):
- super(vkmodel,self).__init__()
- self.layer1=nn.Sequential(
- nn.Conv2d(in_channels=1,out_channels=64,kernel_size=3,padding=1),
- nn.ReLU(),
- nn.MaxPool2d(kernel_size=2)
- )
- self.layer2=nn.Sequential(
- nn.Conv2d(in_channels=64,out_channels=128,kernel_size=3,padding=1),
- nn.ReLU(),
- nn.MaxPool2d(kernel_size=2)
- )
- self.layer3=nn.Sequential(
- nn.Conv2d(in_channels=128,out_channels=256,kernel_size=3,padding=1),
- nn.ReLU(),
- nn.MaxPool2d(kernel_size=2)
- )
- self.layer4=nn.Sequential(
- nn.Conv2d(in_channels=256,out_channels=512,kernel_size=3,padding=1),
- nn.ReLU(),
- nn.MaxPool2d(kernel_size=2)
- )
- self.layer5=nn.Sequential(
- nn.Flatten(),
- nn.Linear(in_features=6144,out_features=4096),
- nn.Dropout(0.2),
- nn.ReLU(),
- nn.Linear(in_features=4096,out_features=captcha_size*captcha_array.__len__())
- )
- def forward(self,x):
- x=self.layer1(x)
- x=self.layer2(x)
- x=self.layer3(x)
- x=self.layer4(x)
- x=self.layer5(x)
- return x
-
- class my_dataset(Dataset):
- def __init__(self,root_dir) -> None:
- super(my_dataset,self).__init__()
- self.image_path=[os.path.join(root_dir,image_name) for image_name in os.listdir(root_dir)]
- self.transforms=transforms.Compose(
- [
- transforms.ToTensor(),
- transforms.Resize((47,100)),
- transforms.Grayscale()
- ]
- )
- def __len__(self):
- return self.image_path.__len__()
- def __getitem__(self, index):
- image_path=self.image_path[index]
- image=self.transforms(Image.open(image_path))
- label=image_path.split('\\')[-1]
- label=label.split("_")[0]
- label_tensor=text2Vec(label)
- label_tensor=label_tensor.view(1,-1)[0]
- return image,label_tensor
-
- class Predict():
- def __init__(self,modelPath) -> None:
- self.device='cuda' if torch.cuda.is_available() else 'cpu'
- self.detector = torch.load(modelPath, map_location=torch.device(self.device), weights_only=False)
- self.detector.eval()
- self.trans=transforms.Compose(
- [
- transforms.Resize((47,100)),
- transforms.Grayscale(),
- transforms.ToTensor(),
- ]
- )
- def predict(self,img:Image.Image):
- if img.mode=='RGBA':
- fill_color = (255,255,255)
- background = Image.new(img.mode[:-1], img.size, fill_color)
- background.paste(img, img.split()[-1])
- img = background.convert("RGB")
- img_tensor=self.trans(img).to(self.device)
- img_tensor=img_tensor.reshape((1,1,47,100))
- output=self.detector(img_tensor)
- output=output.view(-1,captcha_array.__len__())
- output_label=vec2Text(output)
- return output_label
- if __name__=='__main__':
- device='cuda' if torch.cuda.is_available() else 'cpu'
- train_dataset=my_dataset(os.path.join(os.getcwd(),r'datasets\train'))
- train_dataloader=DataLoader(dataset=train_dataset,batch_size=40,shuffle=True)
- w=SummaryWriter("log")
- loss_fn=nn.MultiLabelSoftMarginLoss().to(device)
- vk=vkmodel().to(device)
- optim=Adam(vk.parameters(),lr=0.001)
- total_step=0
- for epoch in range(10):
- print("训练epoch{}".format(epoch))
- for i,(images,labels) in enumerate(train_dataloader):
- images=images.to(device)
- labels=labels.to(device)
- vk.train()
- outputs=vk(images)
- loss=loss_fn(outputs,labels)
- optim.zero_grad()
- loss.backward()
- optim.step()
- total_step+=1
- if i%100==0:
- print("训练次数{},{}".format(i,loss.item()))
- w.add_scalar("loss",loss,total_step)
- torch.save(vk,os.path.join(os.getcwd(),"model.pth"))
|







 AutoStudyXFK_v1.1.zip(355.78 KB, 下载次数: 142)2025-6-11 00:11 上传
AutoStudyXFK_v1.1.zip(355.78 KB, 下载次数: 142)2025-6-11 00:11 上传

 速速细嗦
速速细嗦